บทนำ
Host Health Monitoring บน Sangfor Cloud Platform (SCP) ประกอบด้วย 2 ส่วนหลัก ได้แก่ Host Health สำหรับตรวจจับ node ที่ไม่แข็งแรง (hung node หรือ node ที่มีความเสี่ยงจะ hang) และ Network Health สำหรับตรวจจับ packet loss และ latency ของ network link ระหว่าง node ช่วยป้องกันปัญหา node crash, system hang และ service interruption
ข้อกำหนดเบื้องต้น
- สำหรับ Network Health: ไม่สามารถระบุว่า interface สุขภาพดีหรือไม่ภายใน 15 นาทีหลัง deploy SCP environment
ขั้นตอนการตั้งค่า
1. Host Health
HCI สามารถตรวจจับและแสดง unhealthy node โดยอัตโนมัติ โดย node ที่ไม่แข็งแรงจะไม่ถูกเลือกใช้สำหรับ VM startup, HA และงานอื่นๆ สำหรับ cluster capacity expansion, node replacement และสถานการณ์อื่นๆ SCP จะตรวจจับ hardware เพื่อป้องกัน node crash หรือ system hang จาก hardware failure
- เข้าสู่ระบบ SCP ไปที่ Resources > Reliability > Host Health Monitoring > Unhealthy Nodes เพื่อดู unhealthy physical host
- ไปที่ Health Monitoring เพื่อตั้งค่า Host Health และ Network Health
การตั้งค่า Host Health
-
Unhealth Metrics: หากเปิดใช้งาน Host hardware (CPU, memory, system disk or RAID card) anomaly ระบบจะตรวจจับ:
- ECC Memory, UECC Memory
- Bad Sector in System Disk
- System Disk Read-Only
- Short System Disk Lifetime Remaining
- RAID Card Failure
สามารถ customize crash frequency เพื่อระบุ unhealthy node ตามเกณฑ์ที่กำหนดได้
- Check Schedule: หากเปิดใช้งาน Health Monitoring ระบบจะตรวจสอบอัตโนมัติทุกครั้งที่ host startup หรือ restart และสามารถ customize check interval ได้
- Notification Method: ตั้งค่าที่ Resources > Monitor Center > Alerts > Notification Policies เพื่อรับ email notification เมื่อตรวจพบ unhealthy node
- Recovery Method: ตั้งค่าที่ Resources > Reliability > HA สำหรับ host hardware failure
- Fixing Method: ระบบจะ migrate VM จาก unhealthy node ไปยัง healthy node เท่านั้น โดย VM ที่มี scheduling policy จะถูก schedule ตาม policy ส่วน VM ที่ไม่มี policy จะถูก migrate ไปยัง unhealthy node ที่ค่อนข้างดีกว่า (กลไกนี้ไม่มีผลหากไม่มี healthy node ในคลัสเตอร์ และไม่มีผลกับ NFV device)
- Auto Removal: หากเปิดใช้งาน unhealthy node จะถูกลบออกจากรายการ Unhealthy Nodes โดยอัตโนมัติเมื่อกลับมาแข็งแรง
2. Network Health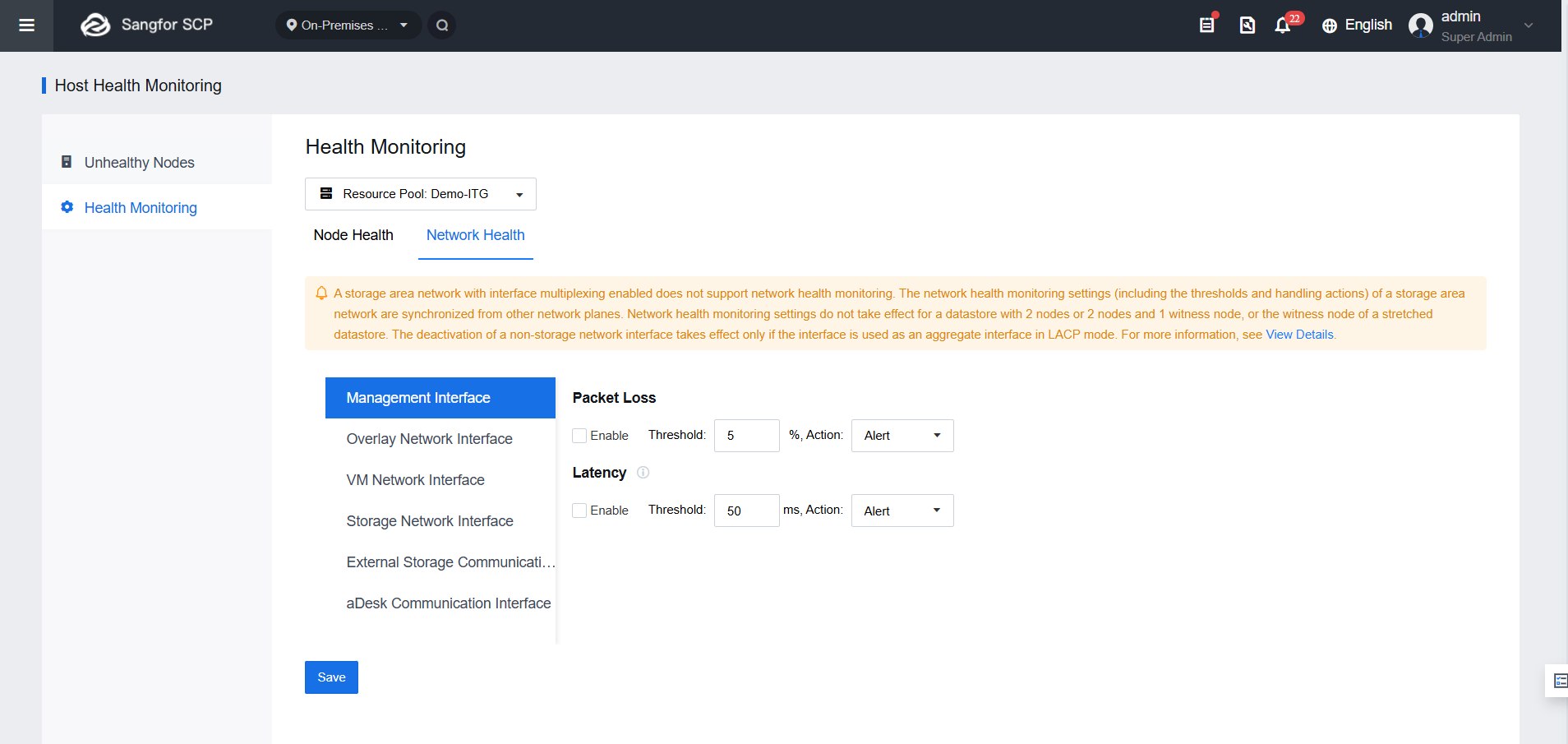
Network health check ของ HCI ตรวจจับ packet loss และ latency ของ network link ผ่าน message ที่ส่งระหว่าง node เมื่อ packet loss rate หรือ latency ถึง threshold ระบบจะสร้าง alert เพื่อป้องกัน service interruption
- เข้าสู่ระบบ SCP ไปที่ Resources > Reliability > Host Health Monitoring > Health Monitoring > Network Health
- ตั้งค่า Packet Loss และ Latency threshold สำหรับ interface ต่างๆ เมื่อถึง threshold จะสร้าง alert
Interface ที่รองรับ Network Health Check
| Interface | Aggregated | Non-Aggregated | Aggregated + Non-Aggregated |
|---|---|---|---|
| Management Interface | รองรับ | รองรับ | รองรับ |
| Overlay Network Interface | รองรับ | รองรับ | รองรับ |
| Edge-Connected Interface | รองรับ | รองรับ | รองรับ |
| Storage Network Interface | รองรับ | รองรับ | ไม่รองรับ |
| aDesk Communication Interface | รองรับ | รองรับ | รองรับ |
หมายเหตุ
- Host Health รองรับเฉพาะการตรวจจับ node hang ที่เกิดจาก hardware failure เท่านั้น
- หาก node hang เกิดจาก memory failure และ restart โดยไม่ใช้ memory ที่ตำแหน่งที่เสีย node จะยังคงแสดงเป็น unhealthy
- รองรับการตั้งค่า VLAN ID สำหรับ interface ในการตรวจสอบ network health (สำหรับ edge-connected interface VLAN ID ต้องไม่ใช่ VLAN ID ของ subinterface)
- รองรับการตรวจสอบ latency ของ physical link ภายนอก server (NIC, optical module, physical transmission media, switch)
- สำหรับ aDesk Communication Interface จะตรวจสอบได้เฉพาะ link ระหว่าง server เท่านั้น
- ไม่รองรับ network health check ระหว่าง: Network link ระหว่าง SCP กับ HCI, Communication network ของ witness node, Heterogeneous cluster (VMware), Physical host ที่จัดการโดย SCP
- รองรับ aggregation mode: master-standby, load sharing และ LACP แต่ไม่รองรับ load sharing ของ Mode 0 (round-robin), link aggregation กับ switch เดียว และ link aggregation กับ two switches
ข้อคิดเห็น
0 ข้อคิดเห็น
โปรด ลงชื่อเข้าใช้ เพื่อแสดงข้อคิดเห็น